- PD
- AC
2,514
309
37
Field
Agricultural and Biological Sciences
Subfield
Animal Science and Zoology
Tweeting AI: A Machine Learning Approach for Bird Species Detection and Classification
Ayonabh Chakraborty1, Pushan Kumar Dutta1![]()
Affiliations

Abstract
The rapid decline in global bird populations has generated an urgent need for efficient and accurate monitoring of avian species. In this study, we propose a novel machine learning approach, Tweeting AI, for the automated recognition of bird species based on their images. To solve this problem, we have used Convolutional Neural Network (CNN). This model is the best regarded in image prediction. In this study, we have used CNN to classify the bird species in which we use a dataset for training and predicting. This system allows us to easily identify the species of any bird that we want to know, and segregate the endangered species to preserve, care and take every possible action for their survival.
Correspondence: papers@team.qeios.com — Qeios will forward to the authors
** A study, analysis, and usage of Machine Learning for the identification of Endangered Species
Ayonabh Chakraborty
Amity School of Engineering and Technology Kolkata Amity University, Kolkata, India
Email: ayoncchakraborty7@gmail.com
PK Dutta
Amity School of Engineering and Technology Kolkata Amity University, Kolkata, India
Email: pkdutta@kol.amity.edu
Keywords: Convolution Neural Networks, bird species detection, avian conservation, environmental monitoring, machine learning, deep learning, model-training.
I. Introduction
Bird species recognition has become a significant issue in today’s date. As birds are part of nature and rapidly adapt to ecological changes, for the common man and for the people involved in this field of study it has become essential to identify birds that we encounter in our day-to-day life. Birds play a crucial role as an element of nature. They help in plant pollination; they eat up a large percentage of insects that come into the way of farming. This way they help in controlling the pests that hamper agricultural production. These are a few of the cost benefits that can be helpful for humans if we protect the birds. The aim of our model is to discover more birds and to identify those that are endangered. The advent of machine learning techniques has opened up new possibilities for detecting bird species more efficiently than ever before. Specifically, by using convolutional neural networks (CNNs), which are capable of identifying patterns within large data sets leading towards improved outcomes over time. This innovative approach that leverages AI-powered technology could significantly improve our understanding of avian ecology while enabling researchers to collect data on birds’ behaviors more accurately thereby enhancing overall productivity levels benefiting both individuals/teams involved and the organization as a whole, ultimately resulting in better outcomes achieved faster than expected otherwise. Objectives and Contributions:
The main objectives as proposed are as follows:
- To develop a machine learning-based approach for detecting bird species based on their vocalizations captured via audio recordings coupled with image analysis capabilities provided by CNN models.
- To evaluate the effectiveness of this approach in accurately classifying various bird species from audiovisual data while ensuring ethical considerations around responsible deployment practices being followed leading towards long-term sustainability goals at the workplace
- To provide real-time insights into how avian populations are changing over time by monitoring their behaviors using advanced AI-powered tools thereby enhancing overall productivity levels benefiting both individuals/teams involved and the organization as a whole, ultimately resulting in better outcomes achieved faster than expected otherwise.
Our proposed research will make several contributions to the field of ecology and conservation biology, including:
- Developing a new method for collecting comprehensive data on birds’ behaviors that is more efficient than traditional survey methods.
- Enabling researchers to monitor changes in bird populations over time more effectively through real-time insights generated via integrated AI-powered technologies from diverse sources such as acoustic signals, images/videos, etc.
- Providing an innovative tool that can be used to assess the impact of environmental factors like climate change or habitat loss on avian biodiversity thereby providing advance warning signs enabling proactive measures taken addressing issues raised by stakeholders involved.
Overall, our proposed study has significant potential in helping us better understand avian ecology while driving innovation forward across multiple domains like environment, health, etc., leading towards better ROI over time. In this paper, we provide a comprehensive study of a machine-learning approach for bird species detection and classification using a CNN algorithm on images. We begin with a brief introduction
to the problem and its significance in the context of bird conservation. We then review the related work in the field, including traditional methods and machine learning-based techniques, with a focus on CNNs for image recognition.
Next, we outline the methodology employed in our study, detailing the data collection and pre-processing steps, the architecture of the CNN, and the model training and validation procedures. We also discuss the performance evaluation metrics used, including accuracy, precision, recall, and F1-score, as well as the confusion matrix.
II. Convolutional Neural Network (CNN)
A Convolutional Neural Network (CNN) is a type of artificial neural network inspired by the visual cortex of the human brain. It consists of multiple layers, including convolutional layers, pooling layers, and fully connected layers. CNNs are specifically designed to efficiently analyze visual data by extracting features hierarchically. Convolutional layers, the core component of CNNs, perform convolution operations on the input image with learnable filters, allowing the network to learn meaningful features and patterns. Pooling layers downsample the spatial dimensions of the feature maps, reducing computational complexity and improving robustness. Fully connected layers connect the extracted features to the final output layer for classification or regression. CNNs incorporate various essential components. Activation functions, such as ReLU (Rectified Linear Unit), introduce non-linearity into the network, enabling better modeling of complex relationships. Batch normalization normalizes the outputs of previous layers, improving the stability and speed of training. Dropout regularizes the network by randomly dropping out units during training, reducing over-fitting. Training a CNN involves two key steps: forward propagation and back propagation. In forward propagation, the network processes the input data through its layers, extracting and transforming features. The final output is compared with the ground truth labels to compute the loss. In back propagation, the gradients of the loss with respect to the network parameters are computed and used to update the weights and biases through optimization algorithms like stochastic gradient descent (SGD). CNNs have had a significant impact on various fields. In computer vision, they excel in tasks like object recognition, image classification, object detection, and segmentation. They enable advancements in autonomous vehicles, facial recognition systems, medical image analysis, and more. CNNs have also found applications in natural language processing, speech recognition, and recommendation systems, demonstrating their versatility beyond image analysis.
III. Literature Review
Bird species detection plays a crucial role in biodiversity monitoring, ecological research, and conservation efforts. With advancements in machine learning, automated methods for bird species detection have gained significant attention. This literature review aims to provide an overview of
the current state of research in bird species detection using machine learning techniques, including the datasets, methodologies, and performance metrics employed in various studies. Several datasets have been utilized for bird species detection, enabling researchers to train and evaluate machine learning models effectively. The most commonly used dataset is the Cornell Lab of Ornithology’s eBird dataset, which provides extensive bird sighting records and associated metadata. Other datasets, such as the XenoCanto dataset, BirdCLEF dataset, and BirdNET dataset, have also been employed, each offering unique bird species recordings and annotations. A wide range of machine learning algorithms and methodologies have been explored for bird species detection. Among the popular approaches are convolutional neural networks (CNNs), which have shown remarkable performance in image-based classification tasks. CNN-based architectures, such as ResNet, VGG, and Inception, have been adapted and fine-tuned for bird species detection. Other techniques, such as support vector machines (SVMs), random forests, and hidden Markov models (HMMs), have also been utilized for audio-based classification and bird sound analysis. Feature extraction and representation are critical in capturing relevant information from bird species data. For image-based approaches, features like local binary patterns (LBPs), color histograms, and spectrogram representations have been employed to capture the visual characteristics of birds. In audio-based approaches, Melfrequency cepstral coefficients (MFCCs), mel-spectrograms, and wavelet transform features have been used to extract relevant acoustic information. Hybrid approaches that combine visual and acoustic features have also been explored to improve the accuracy of bird species detection. Evaluation of bird species detection models involves the use of various performance metrics. Accuracy, precision, recall, and F1-score are commonly used to measure the overall performance of the classification models. In addition, confusion matrices and receiver operating characteristic (ROC) curves provide insights into the model’s ability to distinguish between different bird species. Some studies have also focused on evaluating the transferability of models across different geographical regions and seasons.
IV. Methodology
To deal with numerous datasets involving different kinds of bird species, we have made use of the deep neural network known as Convolutional Neural Network to get accurate outputs. A Convolutional Neural Network is a type of neural network that specializes in processing data that has topology in the format of grids. As such, a simple example of a grid-like topology would be that of an image. To define an image in layman’s terms, an image is basically the binary representation of visual data that we can perceive with our eyes or can be captured using devices like a camera, a video recorder, etc. An image consists of pixels arranged in a grid-type format that contains pixel values to denote how bright and what color each pixel should be. Our minds, or to be more scientifically accurate,
the human brain can understand, interpret, and classify a large amount of information when we lay our eyes on any object or image. From grasping simple things like shape or color to forming distinctions between similar-looking objects based on unique properties, the human brain acts like a machine, where each neuron has its own receptive field that it works on and then passes on the data or information gathered by it to the other neurons that are connected to it, leading to the coverage of the entire visual field. Convolutional Neural Network works in a similar manner. In fact, it is so similar to the human brain that just as a biological neuron responds to any signals in the restrictive region of the visual field, each neuron in CNN can process the data limited to its own receptive field. Now based on the requirement of training the model, the CNN layers may consist of many different things like shape, size, color, lines, curves, objects, faces, sceneries, etc. In a certain sense, with the proper usage of Convolutional Neural Networks, we are basically providing computers the ability to perceive using sight. The Convolutional Neural Network model is built to work on data in the form of images. The data can be one-dimensional, two-dimensional, or sometimes while dealing with more features, it can be three-dimensional too. There are various applications of Convolutional Neural Networks including image classification, object detection, medical image analysis, natural language processing, live detection of objects in motion, and filtering out necessary information from junk data. Finally, in the various forms of computer vision projects. The Convolutional Network works in two parts, i.e., Feature Extraction and Classification, where feature extraction is the feature mapping of the dataset based on the application of the activation function on the dataset, which is followed by the pooling of the classes (as per the number of classes present in the dataset), which leads to the classification phase consisting of the final pooling layer before leading it to the output. The convolutional neural network consists of four layers: -
A. Convolutional Layer
This is the major layer that is put to use in convolutional neural networks. Convolution is the basic function of applying a filter on input that results in activation. When we repeatedly apply the same filter to an input, it results in a series of activations known as a feature map. This helps us in finding the locations and the strengths of an identified feature in input, such as an image. The main aim of convolutional neural networks is to automatically learn about a large number of filters based on a training dataset, where the learning, or as we term it “training” can finally be used to identify any type of image that is being provided as an input to test the functioning of the machine learning model. The filters can be handcrafted, namely line detectors or as we see in this case, the labels that have been used to help in identifying any image that is used to test the model in the future. The learnable filters are also sometimes referred to as kernels, and these kernels have a width and a length and are mostly squares in nature. For the inputs that we take in CNN, the depth is essentially the number of channels in the image, for example, while working
with RGB images, the depth is 3 as it’s 1 for each channel. For any existing volumes present deeper in the network, the resulting depth will be the number of filters applied in the previous layer.
B. Activision Layer
After each filter application layer in CNN, we apply an activation function such as ReLU, ELU, etc. We denote the activation layers with the correct terminologies such as RELU for ReLU, thus making it clear that an activation state is being applied inside the architecture of any said network. The purpose of the activation function is to make the output as nonlinear in nature as possible. The neurons in a neural network work with the weight, the bias, and the activation function that they are in correspondence with. As per the process, we update the weight and the bias of each individual neuron in a neural network. This is done based on the error that may occur at the output. This method is known as Backpropagation, which is the essence of our neural network training. It basically updates the weights and the bias of a neuron (say neuron number b) based on the rate of the error that is found in the previous epoch of neuron (say neuron number a), or the iteration of the model training before the previously mentioned neuron(b). This is done to finely tune the weights to minimize error rates, thus making the machine-learning model more accurate.
C. Pooling Layer
It is done to reduce the volume of the input to make the process of machine learning more tuned. The primary function of this layer is to minimize the spatial size of the input, thus reducing the number of parameters and computations present inside the network. Pooling also helps us to control overfitting, i.e., when the accuracy of the dataset used to train the model (training dataset) is greater than the accuracy of the dataset used for testing the model (testing dataset) which results in lower error rates in the training dataset and higher error outputs in the testing dataset essentially showing the signs of a flawed model. Pooling layers operate on all the depth slices of an input using the max function or the average function. Max pooling is the type of pooling that is typically done in the middle of the architecture of the convolutional neural network. Although we wish to avoid fully connected layers altogether, which is being researched with the introduction of the exotic micro-architectures in this field.
D. Fully Connected Layers
These layers are connected to all the activations that have taken place in the previous epoch, which is the standard for all feed-forward neural networks. These are placed at the end of the network.
E. Batch Normalization
This layer of the convolutional neural network is done to normalize the activations of an input volume before passing it to the next layer of the Neural Network. At testing time,
the mini-batches are replaced by the average that is computed during the training process. This helps us ensure the passage of images seamlessly through our network and yet obtain very accurate results without retaining any biases from the final mini-batch passed through the neural network during the training phase. Batch Normalization has been shown to be extremely effective at reducing the number of epochs iterating during the training of the neural network. It also helps in stabilizing the training, by focusing on a larger variety of learning rates and strengths of regularization. It doesn’t help us in tuning the working of the neural network, although making the learning rates and regularization strengths less volatile, it makes the entire process pretty straightforward. This layer hasn’t been used in our project.
F. Dropout
This is the last layer of the neural network. It is basically just a form of regularization that helps prevent instances of overfitting while increasing testing accuracy, sometimes at the expense of the cost of the training process. Dropouts randomly disconnect input layers from the previous layer to the upcoming layer in the neural network.
V. Selection and Usage of Yolov4 to get Hands-on Experience of How Image Detection Works and Using the Yolov5 CNN Model to Train our Dataset
Our project began with the simple steps of understanding the basics of Neural networks, which consisted of learning to train custom data using the Yolov4 CNN model on regular images and obtaining results. This gave us a direction to proceed with the You-Only-Look-Once algorithm version 5 to train the datasets and thus get much more accurate results on unique data. Yolo is an algorithm that detects and recognizes patterns from various objects in a picture in real-standard time. Object-based image detection is done as a regression problem that provides the probabilities of the classes of the detected images. By employing convolutional neural networks to detect objects in real time, the algorithm works based on a single forward propagation approach through a neural network to detect objects based on the dataset of the images provided to it. There are currently many versions of the YOLO algorithm like tiny YOLO, YOLOv3, YOLOv4, YOLOv5, YOLOv6, etc. The most recent version of YOLO is YOLONAS, an extremely efficient object-detecting model.
A. Importance
Out of many algorithms present that can work on our datasets, we singled out the YOLO algorithm primarily because of its speed. It improves the speed of object detection after every epoch as it predicts objects in real time. Accuracy is one of the main factors we chose for this model: being an extremely efficient prediction technique that minimizes background errors. A trained model is of no use if it can’t perform its basic functions with the optimal desired accuracy
and thus can result in a huge waste of time, resources, and energy. Our main goal was to build a highly accurate model that runs seamlessly with the correct format of data being provided to it, and we have achieved so using the You-OnlyLook-Once algorithm. Adding to the feathers in its hat, YOLO is a state-of-the-art machine learning model that is extremely efficient in learning each individual representation of an object and applying them in real-time object detection.
B. The Working Process of the YOLO Algorithm:
The YOLO algorithm works using three techniques, which are forming Residual Blocks which are then put through Bounding Box Regression and finally, the Intersection over Union technique is applied. 1. Residual Blocks: Firstly, the images are divided into various grids of dimension (NxN). In the below image, there are various grid cells of equal dimensions. Every grid is then used to detect any objects that might be present inside of them. Say if a particular object is detected in a single grid cell of an entire image during the training phase, then that grid will be responsible for detecting the object during the testing phase. 2. Bounding Box Regression: A bounding box is an outline that is applied to an object in an image to basically mark it as unique for future detection purposes. Every bounding box consists of Width, Height, Class, and the bounding box center. YOLO uses a single bounding box regression technique to predict the height, width, center, and class of the various objects. In the image below, it represents the probability of any object that may appear in the bounding box. 3. Intersection over Union: Finally, we make use of the IOU phenomenon in object detection that describes how the boxes overlap. YOLO basically makes use of the Intersection over Union phenomenon to provide an output box that surrounds the object perfectly. Every grid cell is used to predict the bounding boxes and helps in calculating the confidence scores. If the value of IOU is 1, it means that the predicted bounding box is the same as the real box, thus meaning that the algorithm has essentially eliminated the boxes that are not like the real box. In the image given below, there are two bounding boxes present: the green bounding box is used as the predicted box and the blue bounding box represents the real box. The YOLO algorithm ensures that the two bounding boxes are always equal in all manners. Thus, YOLO divides the images into grid cells. Then each grid cell forecasts bounding boxes and provides their confidence scores. Finally, the cells predict the class probabilities to find out the class of each object efficiently.
VI. The Working Process: Experimentation, Data Collection, Code, and Output
We began our experiment by deciding to first try, experiment and understand how YOLOv4 works. So, we initially used the darknet repository. Google Colab was our choice of software, which turned out quite a nice platform to easily access our required files to kickstart our project. So the first thing we did
was to go on Google Colab, open a new notebook, and load the darknet repository. However, it is not recommended at all to load the Colab book without connecting the GPU units for the usage of our choice of Machine Learning Model.
Then we select the type of processor for the machine learning model training. For better efficiency, we switch to Google’s GPU for faster epochs or batch iterations.

Then we click on the connect button to set up the notebook to begin our operations.

A. Experimenting with the Darknet Repositories
We clone the darknet repositories using the following commands.

We check the NVIDIA systems of our machine and see if everything is at par for the upcoming activities.

We run a simple command to check the contents of the darknet file that we loaded in our laboratory.

Now we make use of the make automation tool to ease out our task. The make tool requires a file, termed as Makefile to fulfill a set of requirements by running the needed tasks.

In the above make file, there exist four important parameters whose values need to be updated manually. We do so for the build to use the CUDA (Compute Unified Device Architecture) on our GPUs. CUDA has several benefits as it provides us with parallel hardware to run code, with the drivers most suitable for the process of carrying out the executions. It is essentially a software development kit that has libraries, debuggers, compiling tools, etc. These are used to invoke CPUbased programming into GPU-based programming. The main point of CUDA is to be able to write code and be able to run on compatible multiple parallel architectures, which includes non-GPU hardware too. This massively parallel hardware can be used to run a large number of operations much faster as compared to the CPU, yielding improvements in performance by almost a half. Along with that, the values of cuDNN, OpenCV, and tensor cores are also changed to 1 (from 0). Tensor cores are only applicable when Google Colab allocates GPUs like Titan V. The following commands are used to update the values:
Once the necessary updating for the GPU compilation in the Makefile has been completed, we can proceed on with our builds. It can be done so by simply invoking the “make” command.

Now to test the workings of the YOLOv4 model, we downloaded some pre-trained weights. This is done after the darknet framework has been completely in tune with the machine learning algorithm.

To display the images being taken as input and the output that is being produced, we have written a simple function.

We have made use of our custom input in the machine learning process to check the accuracy of the model, and it was satisfactory.





B. Data Collection
After we got hands-on experience with how YOLO works, we started to collect data for our machine-learning model, which consisted of birds of different species. In the following machine-learning model training and output version, we have made use of some birds by using numerous images of each one of them and labelling all the images manually. All of the labelling happened manually, so it indeed turned out to be a very tedious task. At first, we downloaded the labelImg file from the terminal and then we proceeded to create a virtual environment in Anaconda Command Shell. We proceed to access the folder in which the labelImg resources have been downloaded and by running the necessary commands, we activate the labelImg image labelling software.





Finally, we have to delete all the incompatible image files that cannot be used for the model-training process. Since this task has to be done manually, hence it can be tedious sometimes.
C. Code
Thus, by forming a dataset after collecting and labelling over 600 images, we begin to train our model based on the said dataset. We make use of Google Colaboratory again, and this time we load the YOLOv5 files that are needed for the training of our model.
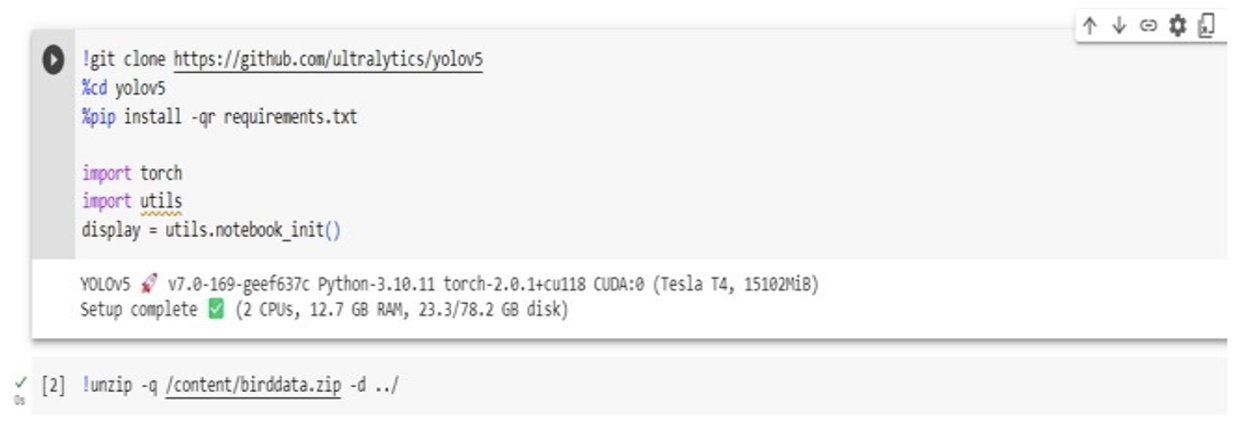
After uploading a zipped folder of our dataset onto Google Colab, we run some commands to unzip it for the training of our model to begin. But before we can proceed to do so, there is a very important task, and that is to form a YAML file that would contain the locations of the training images and the validation images and contains the total number of classes taken into consideration while forming the dataset. Here, we term the YAML file as ‘yx.yaml’.

After we have formed the YAML file and uploaded it on Colab, we begin the training process by iterating the dataset through 300 epochs to get an efficient and accurate object prediction model using image data.





After the training gets completed, it shows the destination folder of the best.pt and the last.pt that contains the activated kernels of the birds present inside of the images. The overall result of the machine learning process is given in the data mentioned below, and a score of mAP50 nearer to 1 means a more recognized class among any particular set of classes.
D. Output
Now, for the final step in our bird recognition training, we supply the model with different test data of birds which it was able to predict with near efficiency almost every time.
















VII. Conclusion and Future Works
We analyze the performance of our proposed approach and compare it with existing methods in the literature. We also address the challenges and limitations encountered, such as variability in image quality and bird poses, and the limited training data available for rare species. Finally, we suggest future work and potential improvements to the proposed
framework, including the incorporation of additional features, the use of transfer learning and pre-trained models, and integration with citizen science platforms. The findings of this study indicate that the proposed CNN-based approach can effectively detect and classify bird species from images, offering a valuable tool for conservationists and researchers working to protect and monitor bird populations. The field of bird species detection using machine learning has witnessed significant advancements, leveraging diverse datasets, methodologies, and performance metrics. These developments have the potential to revolutionize avian biodiversity monitoring, ecological research, and conservation efforts. While substantial progress has been made, there are still challenges to overcome and future directions to explore. Future research should focus on addressing data limitations by collecting and annotating comprehensive data- sets, involving collaborations between researchers and citizen scientists. The integration of multiple sensors and the development of deep learning architectures tailored for audio-based classification hold promise for improving the accuracy and robustness of bird species detection systems. Transfer learning, generalization, and model adaptation techniques should be investigated to ensure the applicability of models across different geographical regions and environmental conditions. Additionally, the development of real-time monitoring systems using lightweight models and IoT technologies can enable timely detection and response to conservation challenges. Future research directions in bird species detection using machine learning offer exciting avenues for advancements in the field. While significant progress has been made, several challenges remain, and further exploration is needed to improve the accuracy, robustness, and applicability of bird species detection systems. The following are key future directions that researchers can pursue:
A. Addressing Data Limitations
One of the main challenges in bird species detection is the scarcity of labeled data, especially for rare and endangered species. Future research should focus on collecting and annotating more diverse and comprehensive datasets, covering various geographical regions and seasons. Collaborative efforts between researchers, citizen scientists, and birding communities can significantly contribute to the availability of labeled data.
B. Multi-Sensor Fusion
Integrating data from multiple sensors, such as images, audio recordings, and environmental variables, holds promise for improving bird species detection accuracy. Future research should explore methods to effectively combine and fuse information from different modalities. This would allow for a more comprehensive understanding of bird presence, behavior, and habitat preferences.
C. Transfer Learning and Generalization
Assessing the transferability of models across different geographical regions, habitats, and recording conditions is an important aspect of bird species detection. Future research should focus on developing models that can generalize well to unseen species and adapt to varying environmental factors. Transfer learning techniques, domain adaptation, and data augmentation strategies can aid in improving the generalization capabilities of bird species detection models.
D. Real-time Monitoring Systems
The development of real-time bird species detection systems can significantly contribute to conservation efforts, allowing for immediate detection and response to potential threats. Future research should explore lightweight and efficient models suitable for deployment on edge devices or in remote monitoring stations. Integration with IoT (Internet of Things) technologies and acoustic sensor networks can enable real-time monitoring of bird populations and their habitats.
VIII. Citations
- [Jmour et al., 2018] [Terven and Cordova-Esparza, 2023] [Bisong et al., 2019]
References
- [Bisong et al., 2019] Bisong, E. et al. (2019). Building machine learning and deep learning models on Google cloud platform. Springer.
- [Jmour et al., 2018] Jmour, N., Zayen, S., and Abdelkrim, A. (2018). Convolutional neural networks for image classification. In 2018 international conference on advanced systems and electric technologies (IC ASET), pages 397–402. IEEE.
- [Terven and Cordova-Esparza, 2023] Terven, J. and Cordova-Esparza, D. (2023). A comprehensive review of yolo: From yolov1 to yolov8 and beyond. arXiv preprint arXiv:2304.00501.
Open Peer Review
